
起首:通义千问Qwen
今天,咱们发布了 Qwen2.5-Omni,Qwen 模子家眷中新一代端到端多模态旗舰模子。该模子专为全见识多模态感知狡计,好像无缝科罚文本、图像、音频和视频等多种输入神志,并通过及时流式反应同期生成文本与当然语音合成输出。
该模子现已在 Hugging Face、ModelScope、DashScope 和 GitHub上开源怒放,你不错通过咱们的Demo体验互动功能,或是通过Qwen Chat 径直发起语音或视频聊天,千里浸式体验全新的 Qwen2.5-Omni 模子重大性能。
主要特色
万能蜕变架构:咱们提议了一种全新的Thinker-Talker架构,这是一种端到端的多模态模子,旨在复旧文本/图像/音频/视频的跨模态领路,同期以流式模式生成文本和当然语音反应。咱们提议了一种新的位置编码时期,称为TMRoPE(Time-aligned Multimodal RoPE),通过期代轴对都收尾视频与音频输入的精确同步。
及时音视频交互:架构旨在复旧全都及时交互,复旧分块输入和即时输出。
当然理会的语音生成:在语音生成的当然性和融会性方面越过了好多现存的流式和非流式替代决策。
全模态性能上风:在同等限制的单模态模子进行基准测试时,发扬出不凡的性能。Qwen2.5-Omni在音频才气上优于访佛大小的Qwen2-Audio,并与Qwen2.5-VL-7B保合手同等水平。
不凡的端到端语音提示侍从才气:Qwen2.5-Omni在端到端语音提示侍从方面发扬出与文本输入科罚相失色的恶果,在MMLU通用常识领路和GSM8K数学推理等基准测试中发扬优异。
Qwen2.5-Omni-7B demo
模子架构
Qwen2.5-Omni接收Thinker-Talker双核架构。Thinker 模块如同大脑,注意科罚文本、音频、视频等多模态输入,生成高层语义表征及对应文本本色;Talker 模块则访佛发声器官,以流式模式接收 Thinker及时输出的语义表征与文本,理会合成打破语音单位。Thinker 基于 Transformer 解码器架构,和会音频/图像编码器进行特征提真金不怕火;Talker则接收双轨自回首 Transformer 解码器狡计,在查验和推理经过中径直接收来自 Thinker 的高维表征,并分享沿途历史迂回文信息,酿成端到端的和解模子架构。
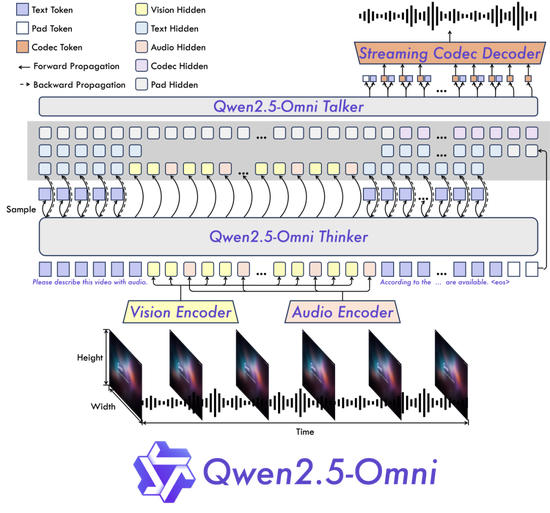
模子架构图
模子性能
Qwen2.5-Omni在包括图像,音频,音视频等多样模态下的发扬都优于访佛大小的单模态模子以及阻滞源模子,举例Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro。
在多模态任务OmniBench,Qwen2.5-Omni达到了SOTA的发扬。此外,在单模态任务中,Qwen2.5-Omni在多个领域中发扬优异,包括语音识别(Common Voice)、翻译(CoVoST2)、音频领路(MMAU)、图像推理(MMMU、MMStar)、视频领路(MVBench)以及语音生成(Seed-tts-eval和主不雅当然听感)。
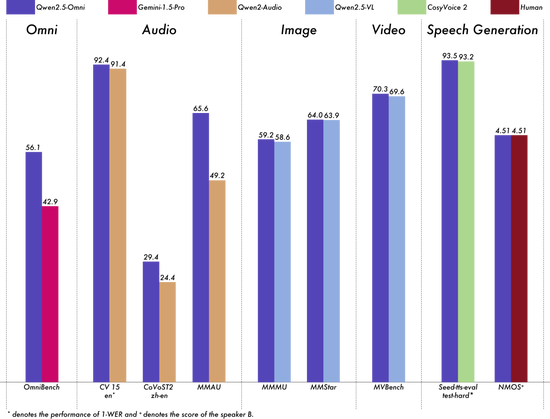
模子性能图
下一步
咱们期待听到您的反馈,并看到您使用 Qwen2.5-Omni 建设的蜕变利用。在不久的未来,咱们将服从增强模子对语音提示的苦守才气,并进步音视频协同领路才气。更值得期待的是,咱们将合手续拓展多模态才气范畴,以发展成为一个全面的通用模子!
体验模式
Qwen Chat:https://chat.qwenlm.ai
Hugging Face:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
ModelScope:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
DashScope:https://help.aliyun.com/zh/model-studio/user-guide/qwen-omni
GitHub:https://github.com/QwenLM/Qwen2.5-Omni
Demo体验:https://modelscope.cn/studios/Qwen/Qwen2.5-Omni-Demo
👇点击‘阅读原文’一键体验全模态及时互动
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
攀扯剪辑:李桐 体育游戏app平台